Introduction
Vercel recently released their Vercel SDK - an open-source library designed to help developers build AI-powered user interfaces in JavaScript and TypeScript. This SDK makes it easy to create conversational, streaming, and chat user interfaces with cutting-edge technologies.
Key Features of Vercel AI SDK
- Edge-ready: Compatible with Vercel’s Edge Network, enabling fast and scalable AI-powered apps.
- Built-in Adapters: First-class support for LangChain, OpenAI, Anthropic, and Hugging Face.
- Streaming First: SWR-powered React hooks for fetching and rendering streaming text responses.
- Stream Callbacks: Callbacks for saving completed streaming responses to a database in the same request.
To illustrate the versatility of the Vercel AI SDK, we’ll build a streaming AI chat app with Next.js in this step-by-step guide.
Experimenting with Large Language Models (LLMs)
Choosing the right large language model (LLM) and fine-tuning prompts are essential for achieving the best results in AI-powered applications. Vercel’s interactive online prompt playground launched in April, provides an excellent opportunity to experiment with 20 open-source and cloud LLMs in real-time.
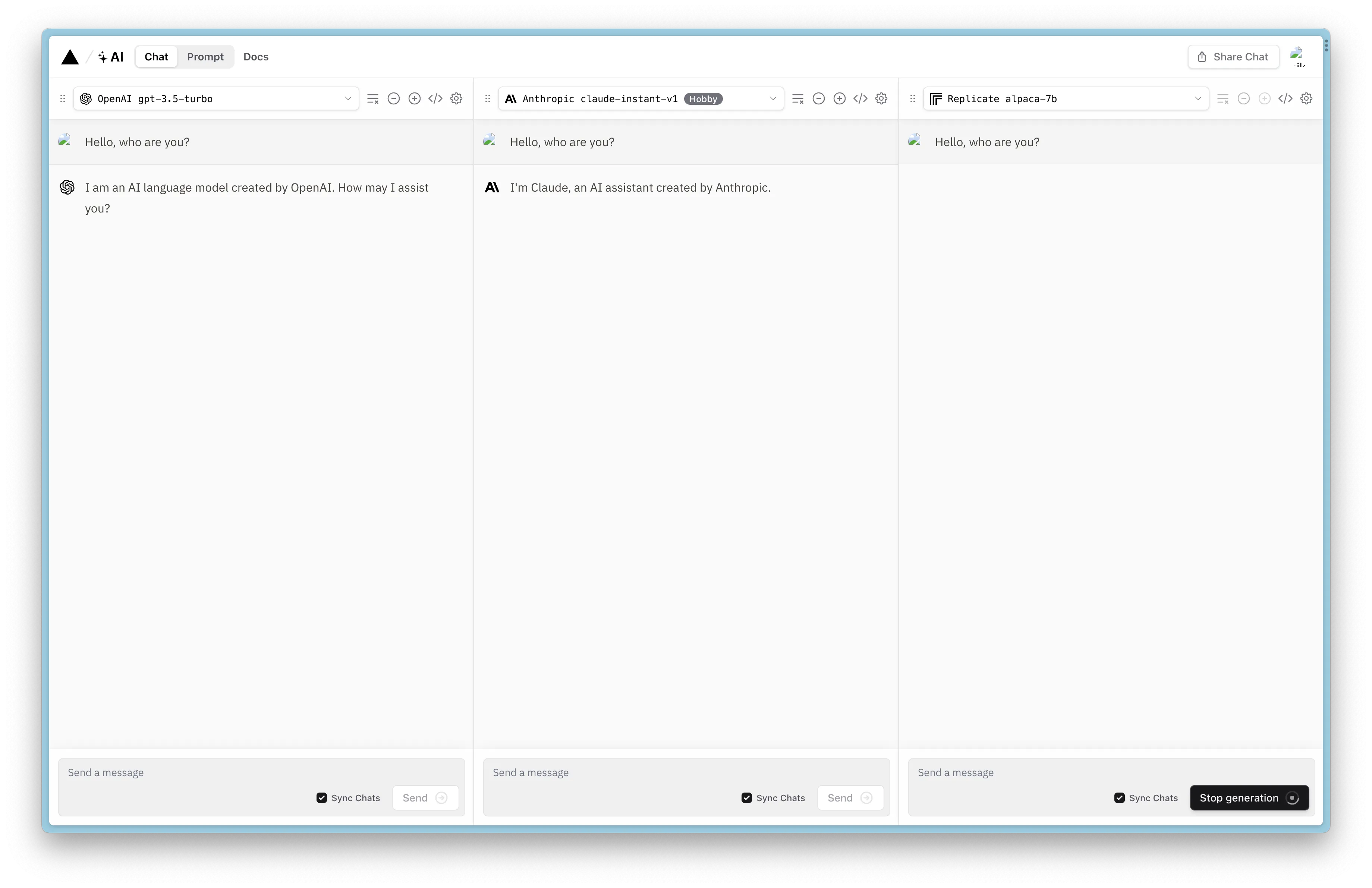
As an developer, you may want to experiment with different prompts, model sizes, and generation parameters, such as temperature and max tokens. Adjusting these factors can significantly change the output of the LLM, ultimately affecting the final user experience of your AI-powered chat app.
To enhance your understanding of the different LLMs and their distinct capabilities, take advantage of Vercel SDK’s official playground to compare how each model responds to the same prompts. As a result, you’ll gain insights into the ideal models and prompt engineering techniques to meet your specific use case requirements.
Emphasize the importance of experimenting with prompts and generation parameters to find the right balance between creativity, relevance, and processing speed. Putting effort into optimizing these factors will not only help you understand the strengths and weaknesses of different models but also pave the way to create more engaging and useful conversational UIs in your applications.
Understanding Streaming in AI Chat Apps
Streaming conversational text UIs, like ChatGPT, have gained massive popularity over the past few months. In this section, we’ll explore the benefits and drawbacks of streaming and blocking interfaces, and how to implement them using the Vercel AI SDK.
Large Language Models (LLMs) are extremely powerful, but they can be slow when generating long outputs. A traditional blocking UI can cause users to wait for several seconds before the entire LLM response is generated. This can result in a poor user experience in conversational applications like chatbots. Streaming UIs can help mitigate this issue by displaying parts of the response as they become available.
- Blocking UI: Waits until the full response is available before displaying it.
- Streaming UI: Transmits and displays parts of the response as they become available.
Streaming UIs can display the response much faster than a blocking UI, as they don’t need to wait for the entire response before showing anything. However, streaming interfaces may not be necessary or beneficial in every case. If you can achieve your desired functionality using a smaller, faster model without streaming, you’ll often have a simpler and more manageable development process.
Regardless of your model’s speed, the Vercel AI SDK makes implementing streaming UIs as simple as possible.
Building a Streaming AI Chat App with Next.js and Vercel AI SDK
In this tutorial, we’re going to build a streaming AI chat app using Vercel AI SDK and Next.js. We’ll provide a more detailed breakdown of each step, ensuring that you can follow along easily.
Step 1: Set up a new Next.js project
First, let’s create a new Next.js project using the latest version with the app router. Run the following command in your terminal:
pnpm dlx create-next-app ai-appDuring the project’s creation process, select TypeScript, ESLint, Tailwind CSS, the src/ directory, and the App Router. Customize the default import alias if you prefer.
Step 2: Install necessary dependencies
Navigate to the project’s directory with cd ai-app and install the required dependencies:
pnpm i ai openai-edgeThe ai package is the Vercel AI SDK that allows us to build edge-ready AI-powered streaming text and chat UIs. The openai-edge package is a TypeScript module for querying OpenAI’s API using the fetch method, instead of Axios.
Step 3: Clean up the project’s boilerplate code
To start fresh, remove the initial code by updating the content of the app/globals.css and app/page.tsx files:
/* app/globals.css */
@tailwind base;
@tailwind components;
@tailwind utilities;// app/page.tsx
export default function Home() {
return <main>Hello World</main>
}Step 4: Add an environment file and API key
Create a new .env.local file using the touch .env.local command. Then, generate an OpenAI API key in the OpenAI dashboard and paste it into the .env.local file.
Step 5: Create a Route Handler for the /api/chat endpoint
In this step, we will create an app/chat/route.ts file to handle the /api/chat endpoint. Perform the following actions:
- Inside the
app/chat/route.tsfile, create an edge-friendly OpenAI API client using the API key from the.env.localfile. - Set the runtime to
edge. - Create a
POSTfunction that will handle the/api/chatendpoint.
// app/chat/route.ts
import { Configuration, OpenAIApi } from 'openai-edge'
import { OpenAIStream, StreamingTextResponse } from 'ai'
const config = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
})
const openai = new OpenAIApi(config)
export const runtime = 'edge'
export async function POST(req: Request) {
const { messages } = await req.json()
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
stream: true,
messages,
})
const stream = OpenAIStream(response)
return new StreamingTextResponse(stream)
}You can pass multiple options to the createChatCompletion request, such as choosing a model, setting the temperature, max tokens, etc. Optional callbacks can save the result of a completion to a database after streaming it back to the user, see examples below:
const stream = OpenAIStream(response, {
onStart: async () => {
// This callback is called when the stream starts
// You can use this to save the prompt to your database
await savePromptToDatabase(prompt)
},
onToken: async (token: string) => {
// This callback is called for each token in the stream
// You can use this to debug the stream or save the tokens to your database
console.log(token)
},
onCompletion: async (completion: string) => {
// This callback is called when the stream completes
// You can use this to save the final completion to your database
await saveCompletionToDatabase(completion)
},
})Step 6: Design the app’s user interface
To create the chat app’s user interface, we will use the useChat function from the ai/react sub-path in the app/page.tsx file. This will allow us to create a simple and functional chat app.
// app/page.tsx
'use client'
import { useChat } from 'ai/react'
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat()
return (
<div className="stretch mx-auto flex w-full max-w-md flex-col py-24">
{messages.map((m) => (
<div key={m.id}>
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<label>
Say something...
<input
className="fixed bottom-0 mb-8 w-full max-w-md rounded border border-gray-300 p-2 shadow-xl"
value={input}
onChange={handleInputChange}
/>
</label>
<button type="submit">Send</button>
</form>
</div>
)
}The useChat hook takes care of appending a user message to the chat history and triggering an API request to the configured endpoint. As new chunks of streamed messages are received, the hook updates the messages state and triggers a re-render for a seamless chat experience.
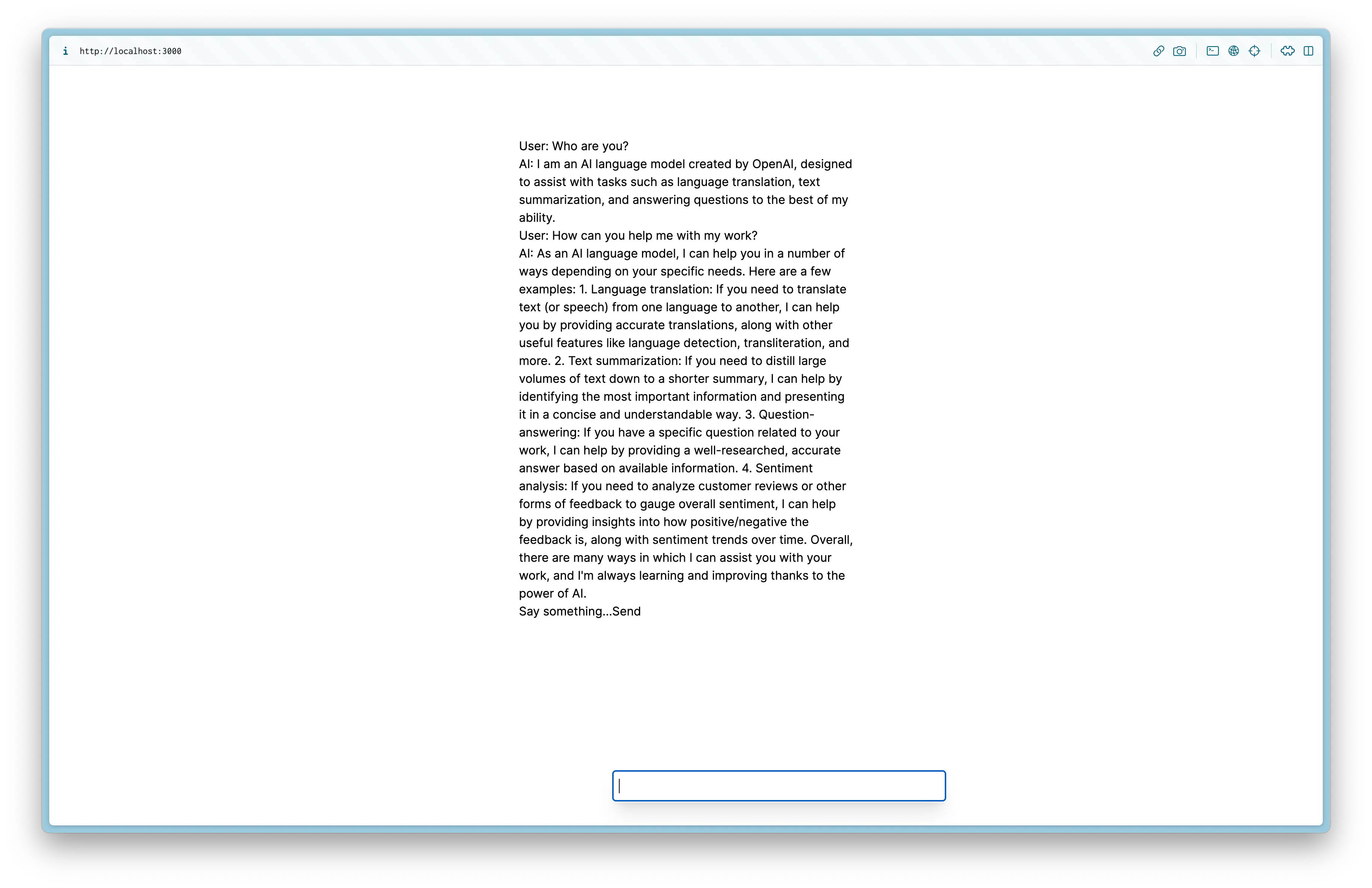
Summary
Congratulations! You’ve successfully built a streaming AI chat app using the Vercel AI SDK and Next.js. Now, users can see the AI response as soon as it’s available, without waiting for the entire response to be received, resulting in an improved chat experience.